
【導(dǎo)讀】深度學(xué)習(xí)技術(shù)對(duì)于降低計(jì)算機(jī)視覺(jué)辨識(shí)和分類的錯(cuò)誤率展現(xiàn)出巨大的優(yōu)勢(shì)。在嵌入式系統(tǒng)中實(shí)施深度神經(jīng)網(wǎng)絡(luò)有助于機(jī)器透過(guò)視覺(jué)解讀臉部表情,并達(dá)到類似人類的準(zhǔn)確度。
辨別臉部表情和情緒是人類社會(huì)互動(dòng)早期階段中一項(xiàng)基本且非常重要的技能。人類可以觀察一個(gè)人的臉部,并且快速辨識(shí)常見(jiàn)的情緒:怒、喜、驚、厭、悲、恐。將這一技能傳達(dá)給機(jī)器是一項(xiàng)復(fù)雜的任務(wù)。研究人員經(jīng)過(guò)幾十年的工程設(shè)計(jì),試圖編寫出能夠準(zhǔn)確辨識(shí)一項(xiàng)特征的計(jì)算機(jī)程序,但仍必須不斷地反復(fù)嘗試,才能辨識(shí)出僅有細(xì)微差別的特征。
那么,如果不對(duì)機(jī)器進(jìn)行編程,而是直接教機(jī)器精確地辨識(shí)情緒,這樣是否可行呢?
深度學(xué)習(xí)(deep learning)技術(shù)對(duì)于降低計(jì)算機(jī)視覺(jué)(computer vision)辨識(shí)和分類的錯(cuò)誤率展現(xiàn)出巨大的優(yōu)勢(shì)。在嵌入式系統(tǒng)中實(shí)施深度神經(jīng)網(wǎng)絡(luò)(見(jiàn)圖1)有助于機(jī)器透過(guò)視覺(jué)解讀臉部表情,并達(dá)到類似人類的準(zhǔn)確度。
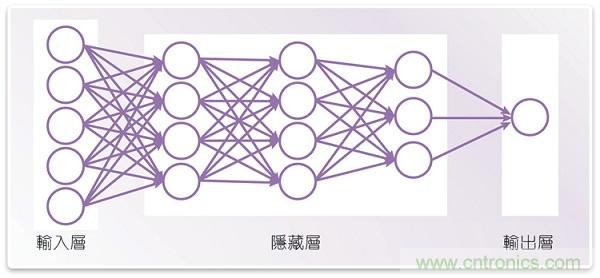
圖1:深度神經(jīng)網(wǎng)絡(luò)的簡(jiǎn)單例子
神經(jīng)網(wǎng)絡(luò)可經(jīng)由訓(xùn)練而辨識(shí)出模式,而且如果它擁有輸入輸出層以及至少一個(gè)隱藏的中間層,則被認(rèn)為具有「深度」辨識(shí)能力。每個(gè)節(jié)點(diǎn)從上一層中多個(gè)節(jié)點(diǎn)的加權(quán)輸入值而計(jì)算出來(lái)。這些加權(quán)值可經(jīng)過(guò)調(diào)整而執(zhí)行特別的影像辨識(shí)任務(wù)。這稱為神經(jīng)網(wǎng)絡(luò)訓(xùn)練過(guò)程。
例如,為了訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)辨識(shí)面帶開心笑臉的照片,我們向其展示開心的圖片作為輸入層上的原始數(shù)據(jù)(影像畫素)。由于知道結(jié)果是開心,網(wǎng)絡(luò)就會(huì)辨識(shí)圖片中的模式,并調(diào)整節(jié)點(diǎn)加權(quán),盡可能地減少開心類別圖片的錯(cuò)誤。每個(gè)顯示出開心表情并帶有批注的新圖片都有助于優(yōu)化圖片權(quán)重。藉由充份的輸入信息與訓(xùn)練,網(wǎng)絡(luò)可以攝入不帶標(biāo)記的圖片,并且準(zhǔn)確地分析和辨識(shí)與開心表情相對(duì)應(yīng)的模式。
深度神經(jīng)網(wǎng)絡(luò)需要大量的運(yùn)算能力,用于計(jì)算所有這些互連節(jié)點(diǎn)的加權(quán)值。此外,數(shù)據(jù)存儲(chǔ)器和高效的數(shù)據(jù)移動(dòng)也很重要。卷積神經(jīng)網(wǎng)絡(luò)(CNN)(見(jiàn)圖2)是目前針對(duì)視覺(jué)實(shí)施深度神經(jīng)網(wǎng)絡(luò)中實(shí)現(xiàn)效率最高的先進(jìn)技術(shù)。CNN之所以效率更高,原因是這些網(wǎng)絡(luò)能夠重復(fù)使用圖片間的大量權(quán)重?cái)?shù)據(jù)。它們利用數(shù)據(jù)的二維(2D)輸入結(jié)構(gòu)減少重復(fù)運(yùn)算。
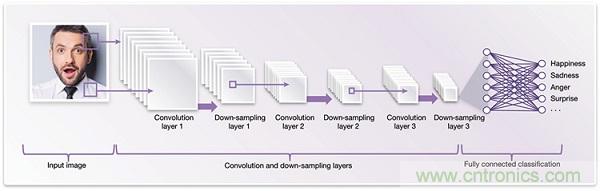
*圖2:用于臉部分析的卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)(示意圖) *
實(shí)施用于臉部分析的CNN需要兩個(gè)獨(dú)特且互相獨(dú)立的階段。第一個(gè)是訓(xùn)練階段,第二個(gè)是部署階段。
訓(xùn)練階段(見(jiàn)圖3)需要一種深度學(xué)習(xí)架構(gòu)——例如,Caffe或TensorFlow——它采用中央處理器(CPU)和繪圖處理器(GPU)進(jìn)行訓(xùn)練計(jì)算,并提供架構(gòu)使用知識(shí)。這些架構(gòu)通常提供可用作起點(diǎn)的CNN圖形范例。深度學(xué)習(xí)架構(gòu)可對(duì)圖形進(jìn)行微調(diào)。為了實(shí)現(xiàn)盡可能最佳的精確度,可以增加、移除或修改分層。
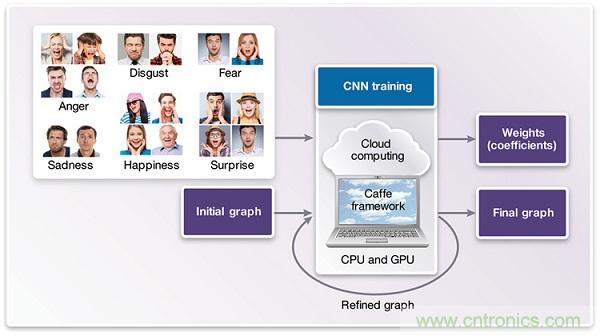
圖3:CNN訓(xùn)練階段
在訓(xùn)練階段的一個(gè)最大挑戰(zhàn)是尋找標(biāo)記正確的數(shù)據(jù)集,以對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練。深度網(wǎng)絡(luò)的精確度高度依賴于訓(xùn)練數(shù)據(jù)的分布和質(zhì)量。臉部分析必須考慮的多個(gè)選項(xiàng)是來(lái)自「臉部表情辨識(shí)挑戰(zhàn)賽」(FREC)的情感標(biāo)注數(shù)據(jù)集和來(lái)自VicarVision (VV)的多標(biāo)注私有數(shù)據(jù)集。
針對(duì)實(shí)時(shí)嵌入式設(shè)計(jì),部署階段(見(jiàn)圖4)可實(shí)施在嵌入式視覺(jué)處理器上,例如帶有可編程CNN引擎的Synopsys DesignWare EV6x嵌入式視覺(jué)處理器。嵌入式視覺(jué)處理器是均衡性能和小面積以及更低功耗關(guān)系的最佳選擇。
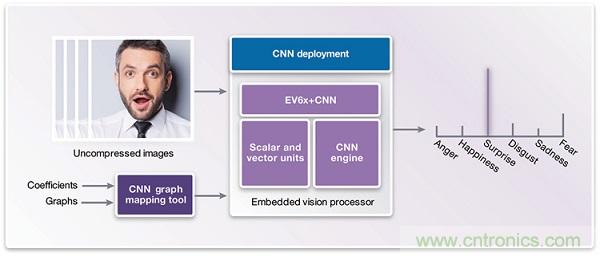
圖4:CNN部署階段
雖然標(biāo)量單元和向量單元都采用C和OpenCL C(用于實(shí)現(xiàn)向量化)進(jìn)行編程設(shè)計(jì),但CNN引擎不必手動(dòng)編程設(shè)計(jì)。來(lái)自訓(xùn)練階段的最終圖形和權(quán)重(系數(shù))可以傳送到CNN映射工具中,而嵌入式視覺(jué)處理器的CNN引擎則可經(jīng)由配置而隨時(shí)用于執(zhí)行臉部分析。
從攝影機(jī)和影像傳感器擷取的影像或視訊畫面被饋送至嵌入式視覺(jué)處理器。在照明條件或者臉部姿態(tài)有顯著變化的辨識(shí)場(chǎng)景中,CNN比較難以處理,因此,影像的預(yù)處理可以使臉部更加統(tǒng)一。先進(jìn)的嵌入式視覺(jué)處理器的異質(zhì)架構(gòu)和CNN能讓CNN引擎對(duì)影像進(jìn)行分類,而向量單元?jiǎng)t會(huì)對(duì)下一個(gè)影像進(jìn)行預(yù)處理——光線校正、影像縮放、平面旋轉(zhuǎn)等,而標(biāo)量單元?jiǎng)t處理決策(即如何處理CNN檢測(cè)結(jié)果)。
影像分辨率、畫面更新率、圖層數(shù)和預(yù)期的精確度都要考慮所需的平行乘積累加數(shù)量和性能要求。Synopsys帶有CNN的EV6x嵌入式視覺(jué)處理器采用28nm制程技術(shù),以800MHz的速率執(zhí)行,同時(shí)提供高達(dá)880MAC的性能。
一旦CNN經(jīng)過(guò)配置和訓(xùn)練而具備檢測(cè)情感的能力,它就可以更輕松地進(jìn)行重新配置,進(jìn)而處理臉部分析任務(wù),例如確定年齡范圍、辨識(shí)性別或種族,并且分辨發(fā)型或是否戴眼鏡。
總結(jié)
可在嵌入式視覺(jué)處理器上執(zhí)行的CNN開辟了視覺(jué)處理的新領(lǐng)域。很快地,我們周圍將會(huì)充斥著能夠解讀情感的電子產(chǎn)品,例如偵測(cè)開心情緒的玩具,以及能經(jīng)由辨識(shí)臉部表情而確定學(xué)生理解情況的電子教師。深度學(xué)習(xí)、嵌入式視覺(jué)處理和高性能CNN的結(jié)合將很快地讓這一愿景成為現(xiàn)實(shí)。
(作者簡(jiǎn)介:Gordon Cooper,Synopsys嵌入式視覺(jué)產(chǎn)品行銷經(jīng)理)
推薦閱讀:


